COVID-19 Sounds App
< Research Updates
30,000 audio recordings (and counting!)
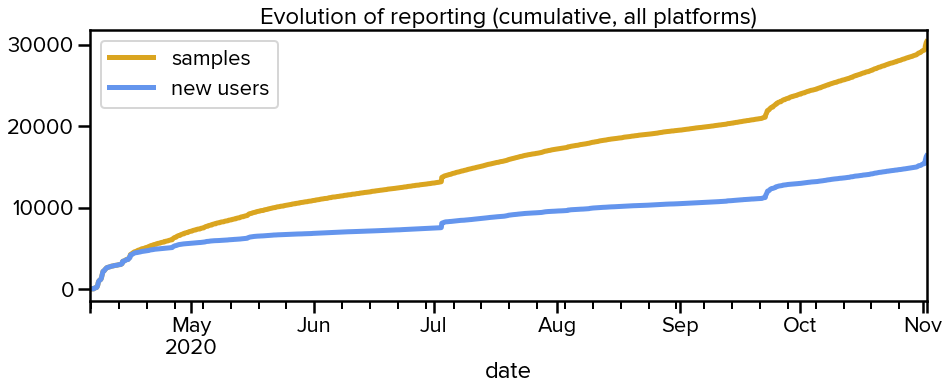
November 1, 2020 — As of today, the COVID-19 Sounds study app has more than 16,000 people contributing over 30,000 audio recordings and symptoms to the fight against COVID! This makes our study one of the biggest crowdsourced health sound projects in the world. Thanks to all of you who are contributing to cutting edge AI-driven COVID research!
Back in April, we launched the apps which attracted thousands of participants from all over the world who continue to use it for months. Here, we take a deep dive in the demographics of the participants and discuss why longitudinal reporting is of utmost importance for our research.
Early results are promising
By now, based on indications of audible respiratory changes in the voice of patients such as dryer coughing, we leveraged sound data to train predictive models. Some initial results are described in a paper published in ACM KDD 2020, where we showed that the combination of breath and cough can predict COVID-19 with nearly 80% accuracy (area under the curve, AUC). However, given the limited access to testing last spring, we had to restrict ourselves to a small subset of all the data collected, to manage the fact that the proportion of COVID-19 positive reported users is considerably smaller than the rest of the users.
The value of long-term reporting
We are currently working on AI models that take into account data from all our participants as they evolve over time. But who are these participants?
Our multiplatform app has seen stable growth in new and existing users over the past months, mostly helped by TV appearances and coverage in online media at an international level (e.g. recently in The Guardian). A user can report every couple of days, hence we have collected 30,345 samples (that is, a single session where the app records coughing, breathing and speech, along with symptoms and an optional location sample).
As in every mobile app, users display different behaviors. Some use our app a couple of times and then drop out, while others keep reporting for months (!). As we see in the figure below, a critical mass of 278 users has provided more than 10 recordings (3 weeks of data).
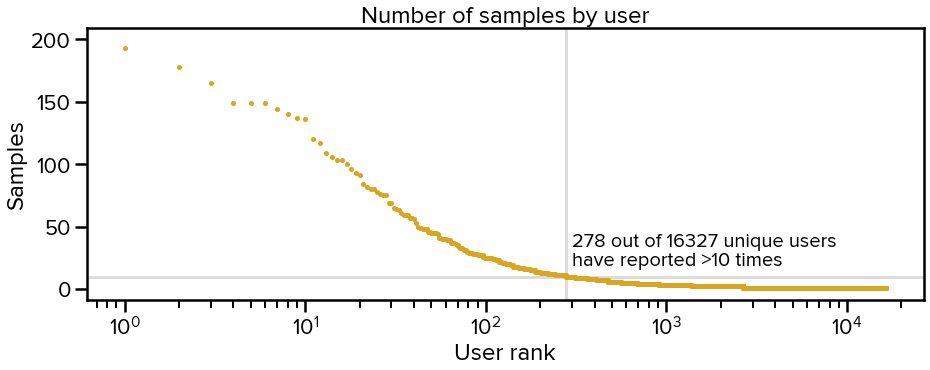
Note that the long tail of single-sample reports comes from the web application which by design does not allow for repeated reporting. Mobile-based long-term reporting is incredibly useful to our ongoing research since it helps us model the personalized evolution of the changes in the voice, even before someone develops symptoms. There are similar efforts to ours out there by academic and private organisations but none of them has focused on long-term reporting.
Demographics of the cohort
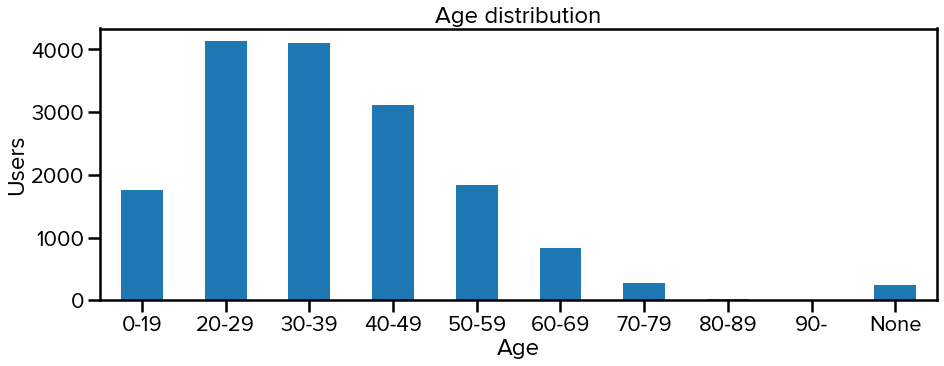
The majority of the users are middle-aged (around 20-50 years old), matching the population distribution of most western countries. Nevertheless, since COVID disproportionately affects the elderly, we still need more people over the age of 60 to participate in our study.
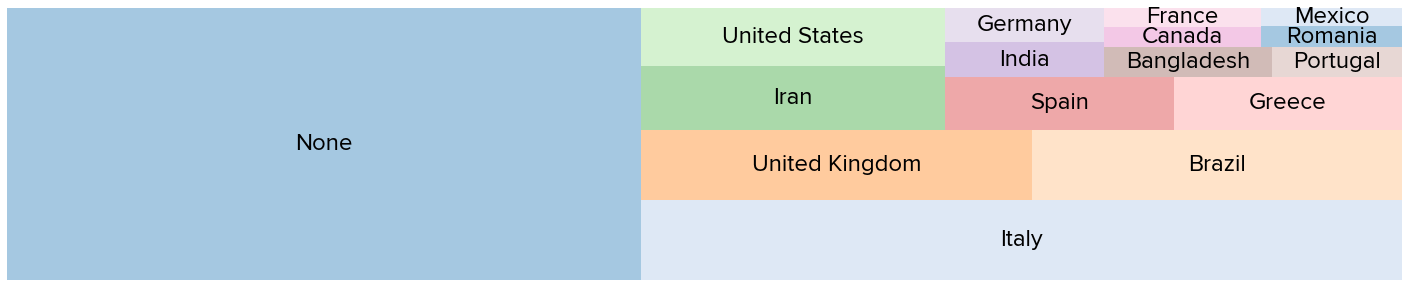
The country distribution, on the other hand, paints a different picture in terms of the global reach of our study. Below, we see a treemap of the top countries that contributed more than 60 unique users (all platforms). A big portion -mostly using the web app- chose not to disclose their location (None), while the rest of users are based in Italy (1738), the UK (764), Brazil (735), Iran (542), USA (497), Greece (342), Spain (331), and more. Our website (one platform) has recorded visits from 198 distinct countries, pretty much every country in the world!
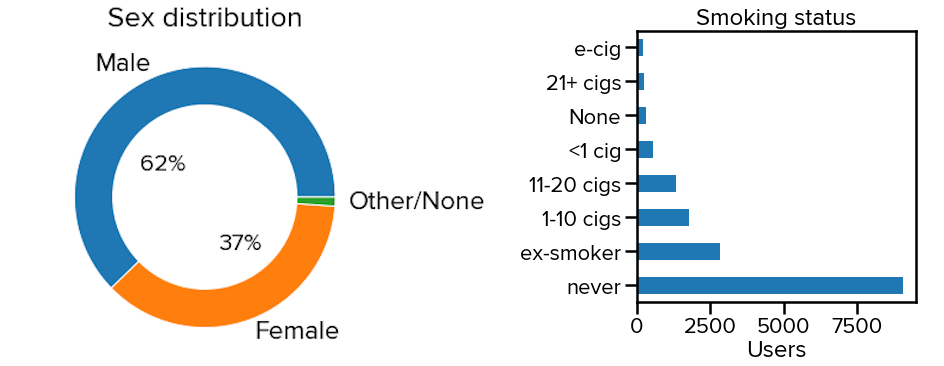
Our sample skews slightly male (62%). Further, given the impact of smoking on respiratory diseases and therefore the potential sound alterations, we ask users to report their smoking status. The majority are no smokers but there are smaller groups of ex- and current casual smokers.
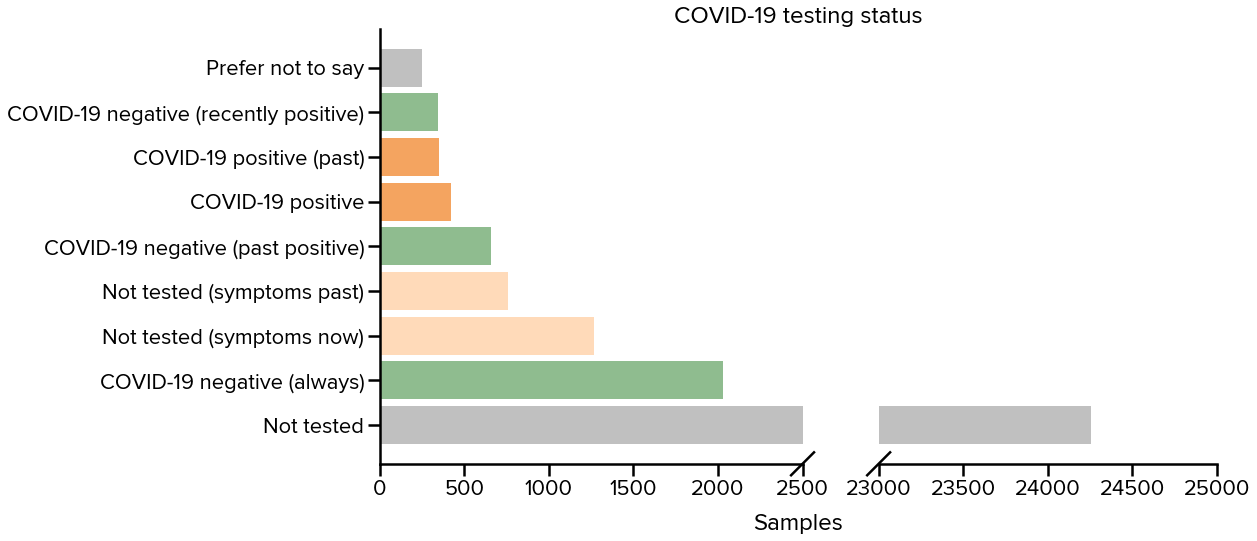
Last, probably the most important data point we collect is the current testing status. In the figure below, we group all longitudinal samples into 8 main categories. Predictably, the large majority has not been tested but a portion thereof has reportedly displayed COVID symptoms at some point. Then, negative users, the control group in our models, contribute almost 3100 samples on aggregate (some of them have recovered from recent infection). On the other hand, currently or recently positive users contribute around 800 samples.
Contribute to vital COVID-19 research
The quality of this dataset is crucial in order to develop non-invasive screening digital tools with unlimited throughput, which -unlike PCR tests- are essentially free and can achieve population-level monitoring in real-time.
As unfortunately most countries enter the second wave of the virus, it would be incredibly useful to participate in our study by taking 1 minute every couple of days, even if you are well. To this end, you can download the Android and iOS applications.