COVID-19 Sounds App
< 研究进展
Uncertainty-aware COVID-19 detection
June 28, 2021 — To what extent can we trust artificial intelligence (AI) models when used as an automatic screening tool for COVID-19? Our previous investigations have shown great promise in leveraging voice and respiratory sounds to detect COVID-19 in a rapid, non-invasive, and affordable manner. Yet, stepping out into the real world with these algorithms calls for solid risk management strategies. Given potential confounders such as noise and sound distortion, error and uncertainty awareness become essential in building trust in these systems in presence of false predictions.
To this purpose, we present our new findings on incorporating uncertainty estimation towards a pragmatic COVID-19 detection from sounds via deep learning models. The initial results are described in a research article accepted for publication at the leading speech processing conference INTERSPEECH 2021.
Method
In this study, we analyse a subset of 330 tested-positive and 919 tested-negative English-speaking participants. Our investigation shows how self-recorded sounds (cough, breathing, and speech) can be used to predict COVID-19, and provides predictive uncertainty indicating to what degree the model is certain about the prediction.
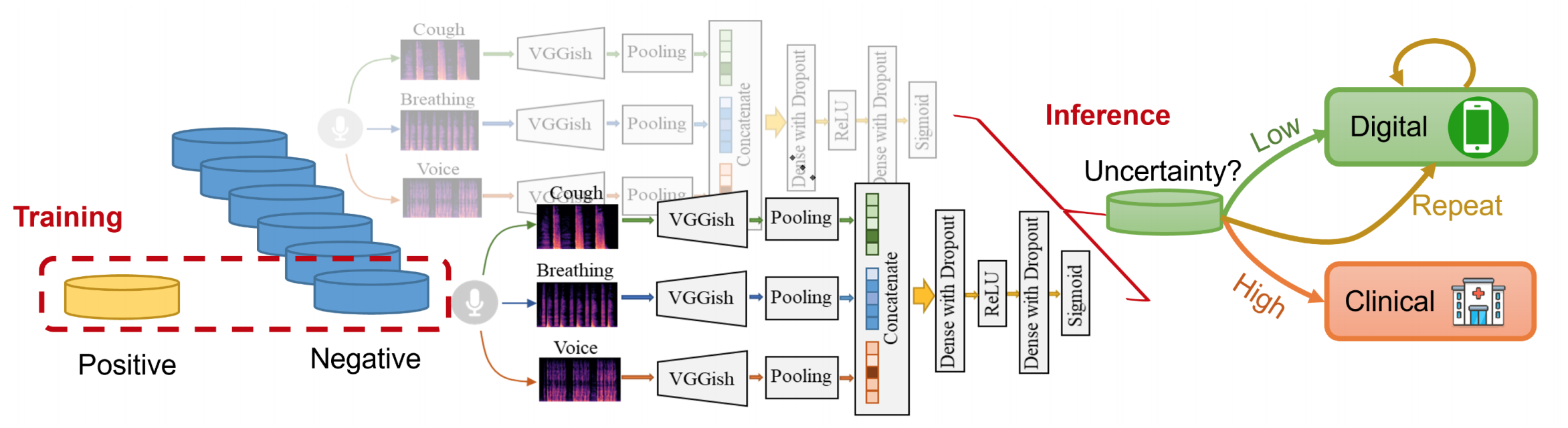
We propose an ensemble learning framework which in the training phase addresses the common issue of data imbalance, and during inference provides predictive uncertainty materialized as the variance in the predictions yielded by the ensemble of models. The backbone model is a pre-trained convolutional network named VGGish1 modified to receive spectrograms of the three sounds as input. As shown in the figure, during training, we generate several balanced training sets out of the big imbalanced datasets. The majority class is sampled without replacement and is fixed for each specific model in the ensemble.
During inference, we make use of the disagreement across the ensemble predictions as a measure of uncertainty2. Highly uncertain predictions can be identified and used as a trigger to ask for a repeated smartphone testing or referred for clinical testing. As a consequence, our framework improves the overall system performance and patient safety at the same time.
Findings
In this work, 10 deep learning models are trained and aggregated into an ensemble model, yielding an AUC of 0.74 with a sensitivity of 0.68 and a specificity of 0.69, which outperforms every single model. For comparison, we also apply this ensemble strategy to our previous SVM-based model (ICASSP paper), reaching an AUC of 0.66. On one hand, we validate the superiority of deep learning against hand-crafted features for audio-based COVID-19 detection. On the other hand, we show that the ensemble of SVMs further boosts the performance of a single SVM model since samples are utilized more efficiently.
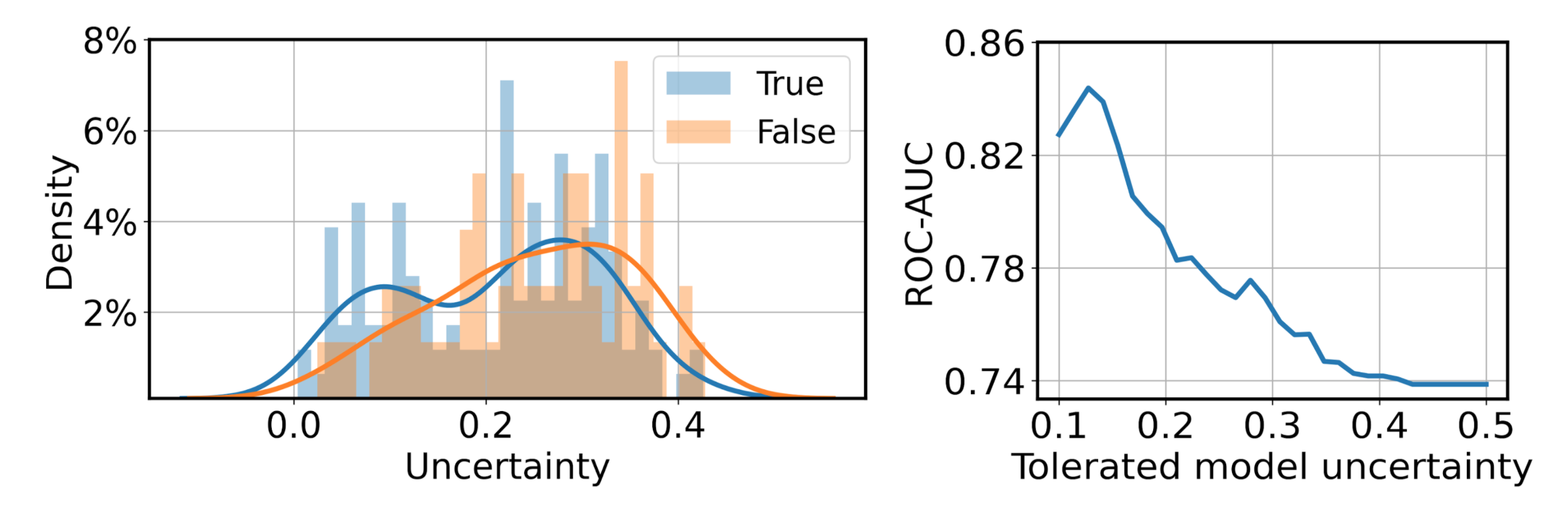
Simultaneously, predictive uncertainty, represented as the variance in the ensemble prediction, is obtained for each audio recording. We show that false predictions often yield higher uncertainty (see the above left figure), enabling us to leverage an empirical uncertainty threshold to suggest the users to repeat the audio test on their phones or take additional clinical tests if the digital diagnosis still fails (see the right figure). By incorporating uncertainty into the automatic diagnosis system, better risk management and more robust decisions can be achieved.
Contribution
To the best of our knowledge, this is the first work exploring the benefits of uncertainty estimation in audio-based COVID-19 detection. This study paves the way for a more robust COVID-19 automated screening system. For future work, we plan to gain a deeper understanding of the estimated uncertainty, exploring how each modality contributes to the overall uncertainty. We are in the process of sharing more data with the research community and we will keep updating our open-source repositories with the latest code on Github.
How to cite our paper
Tong Xia, Jing Han, Lorena Qendro, Ting Dang, Cecilia Mascolo. "Uncertainty-Aware COVID-19 Detection from Imbalanced Sound Data." arXiv preprint: 2104.02005 (2021) [PDF]. To appear in the proceedings of Interspeech 2021.
[1] Shawn Hershey, Sourish Chaudhuri, et al. CNN architectures for large-scale audio classification. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing (ICASSP), pages 131–135, 2017
[2] Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NeurIPS), pages 6405–6416, 2017